Reinforcement Learning Practice
Implementations of basic RL algorithms
Posted by : Junseo Park on
Category : project
🚀 "Implementation of Basic RL Algorithms" 🌟
Algorithm Test
- Basic RL algorithms were implemented and tested in the OpenAI Gym environment.
- The implemented algorithms are as follows:
DQN, DDQN, Dueling DQN, DDQN + Dueling, PPO, A2C, A3C
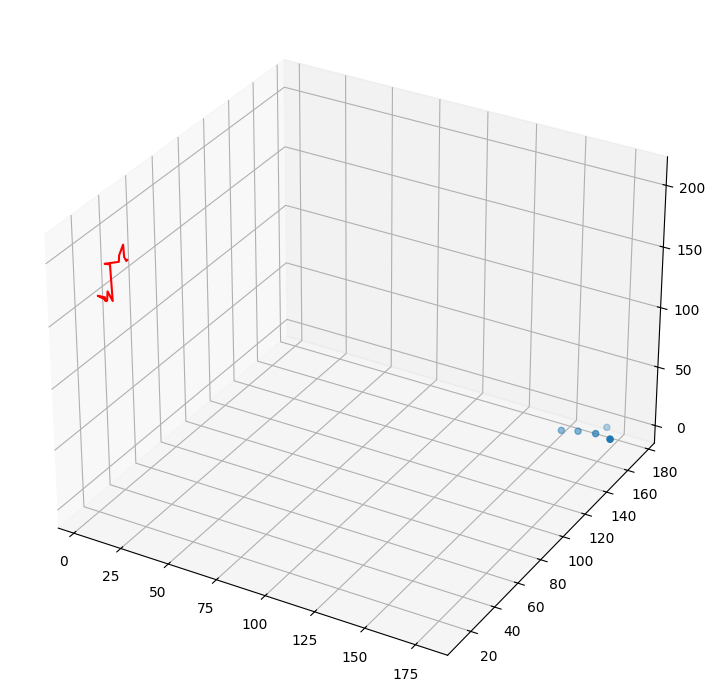
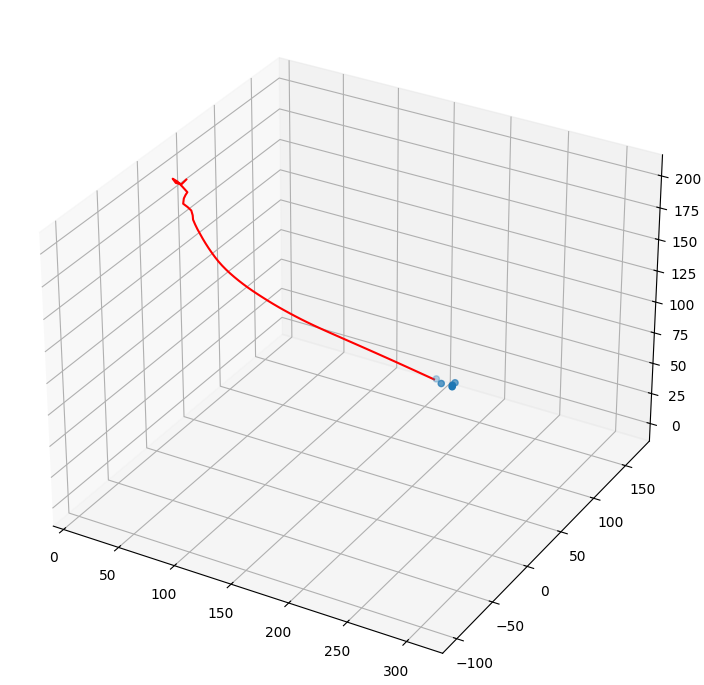
UAV with DDPG
$\textbf{Motivation}$
- A paper presented an experiment where a UAV uses the received signal strength as a reward and employs reinforcement learning (DDPG algorithm) to approach the user.
- The project was carried out with the idea of directly implementing the paper.
$\textbf{Environment}$
- The UAV must reach the user.
- The starting position of the UAV is fixed at ($20, 20, 200$).
- K users (default: $5$) are generated at random positions between [
rd.randint(150, 180), rd.randint(150, 180), 0]. - The DDPG algorithm is used, and the reward is based on the received signal strength between the user and the UAV.
- The network is implemented using a simple DNN.
- The experiment ends after $60$ steps.
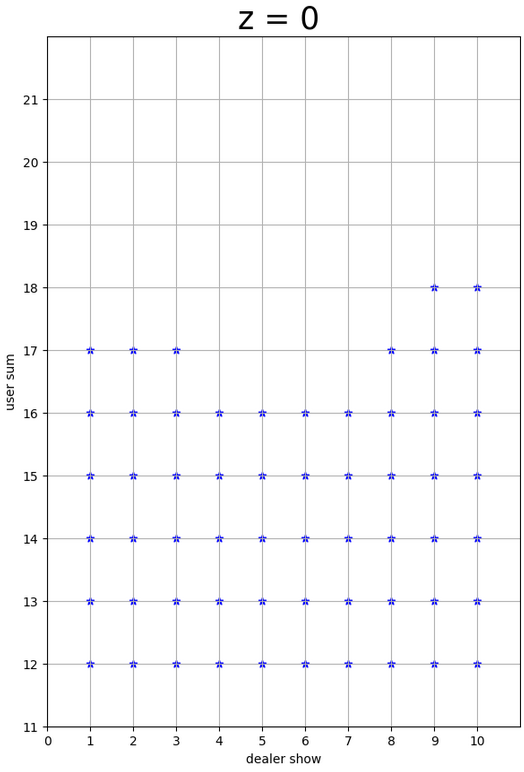
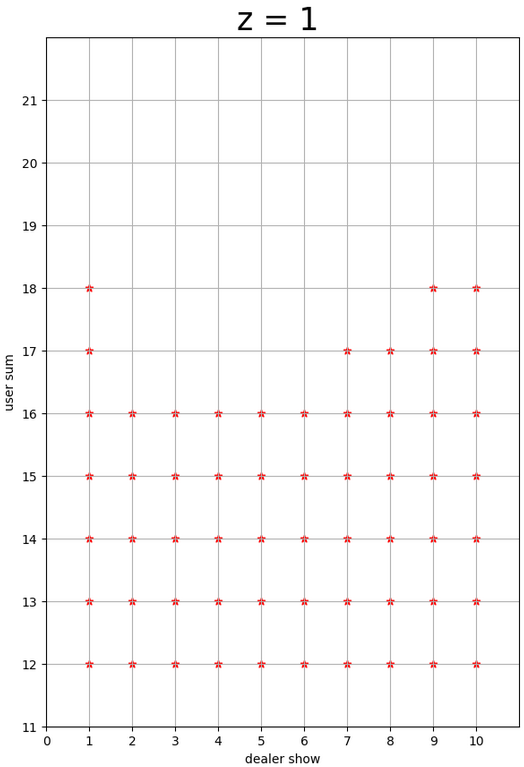
Black Jack with TD vs MC
- TD/MC prediction/control
- The results vary depending on the presence of ACE.
- Areas marked with a star represent “hit,” while the unmarked areas represent “stand.”
Unity with PPO
- Unity provides a service that allows various RL algorithms to be applied to environments created with Unity.
- A car racing environment was created, and the PPO algorithm was applied to test whether it could complete the race.
- The configuration is as follows:
behaviors:
ArcadeDriver:
trainer_type: ppo
hyperparameters:
batch_size: 1024
buffer_size: 204800
learning_rate: 0.0003
beta: 0.005
epsilon: 0.2
lambd: 0.95
num_epoch: 7
learning_rate_schedule: linear
network_settings:
normalize: true
hidden_units: 256
num_layers: 2
vis_encode_type: simple
reward_signals:
extrinsic:
gamma: 0.995
strength: 1.0
keep_checkpoints: 200
max_steps: 100000000
time_horizon: 32
summary_freq: 10000
checkpoint_interval: 50000
Dodge the poop game
$\textbf{Environment}$
-
Action: Move left or right
-
Termination: Terminated when hit by the ball
-
Reward: $-0.01$ over time, $+1$ for small ball, $+10$ for large ball
-
Base network: MLP
-
Algorithms tested:
DQN, A2C, DDPG, A3C, PPO, PPO + RNN, PPO + LSTM, DDQN -
Main result: The task was easy, resulting in good performance from DNN, DDQN, and DQN.
| Method | # of layers | Accelerated epi | Best score | Epi achieved best score | Avg score ($\times 10^2$) |
|---|---|---|---|---|---|
| DQN | 4 | 400 | 1578 | 178 | 150 |
| DQN with CNN | 4 | x | x | x | x |
| DDQN | 4 | 400 | 1729 | 299 | 160 |
| PPO | 5 | 600 | 173 | 200 | 11 |
| PPO with RNN | 5 | x | 45 | 100 | 11 |
| PPO with LSTM | 5 | 5000 | 140 | 205 | 24 |