Robust-QA using DistilBERT
Make a robust QA model on out-of-domain
Posted by : Junseo Park on
Category : project
🚀 "Improving performance on out-of-domain datasets using
i) text data augmentation, ii) AutoML." 🌟
i) text data augmentation, ii) AutoML." 🌟
Context
- The goal of this project is to build a robust Question Answering (QA) model that uses DistilBERT (a lightweight version of BERT) trained on In-domain datasets (SQuAD, NewsQA, Natural Questions) and performs well on unseen Out-domain datasets (DuoRC, RACE, RelationExtraction).
- Train Dataset: $242,304$ (SQuAD, NewsQA, Natural Questions)
- Validation Dataset: $38,888$ (SQuAD, NewsQA, Natural Questions)
- Test Dataset: $721$ (DuoRC, RACE, RelationExtraction)
- The evaluation metrics are F1 Score and Exact Match (EM).
- Baseline (DistilBERT)
- F1 score: $48.41$
- EM: $31.94$
- Baseline (DistilBERT)
Problem
- Developing a novel and groundbreaking methodology within a limited timeframe (1 month) is challenging.
- Therefore, we focused on simple and intuitive approaches to improve performance.
Proposed Method
- Data augmentation (EDA: Easy Data Augmentation)
- Augmenting text data is a challenging task.
- EDA, initially proposed for classification tasks, maintains the data distribution while augmenting text.
- However, it is not directly suitable for QA tasks, so we modified it as follows:
- Preserve case sensitivity.
- Keep answer words intact and modify only the remaining words.
- Augmenting text data is a challenging task.
EDA Techniques:
- Synonym Replacement (SR): Replace n randomly selected words (excluding stop words) with their synonyms.
- Random Insertion (RI): Choose a synonym of a randomly selected word (excluding stop words) and insert it into a random position in the sentence.
- Random Swap (RS): Randomly pick two words in the sentence and swap their positions.
- Random Deletion (RD): Delete words in the sentence with a probability of $p$.
- AutoML
- We explored various hyperparameters to optimize the model:
- Lr_scheduler: None, LambdaLR, MultiplicativeLR, StepLR, CosineAnnealingWarmUpRestarts
- Optimizer: None, RMSprop, Adam, AdamW, SGD
- Learning rate: $[2e-5, 2e-4]$
- Batch size: {$16, 32, 64$}
- Epochs: $[2, 5]$
- Train: last layer vs + last transformer block vs fine-tuning
- We explored various hyperparameters to optimize the model:
Result
- EDA Results
- An augmentation probability of $p = 0.1$ (10%) caused instability.
- A lower probability, $p = 0.01$ (1%), contributed to more stable performance improvements.
- AutoML Results
- Both SGD Optimizer and Partial Training consistently degraded performance, so they were excluded.
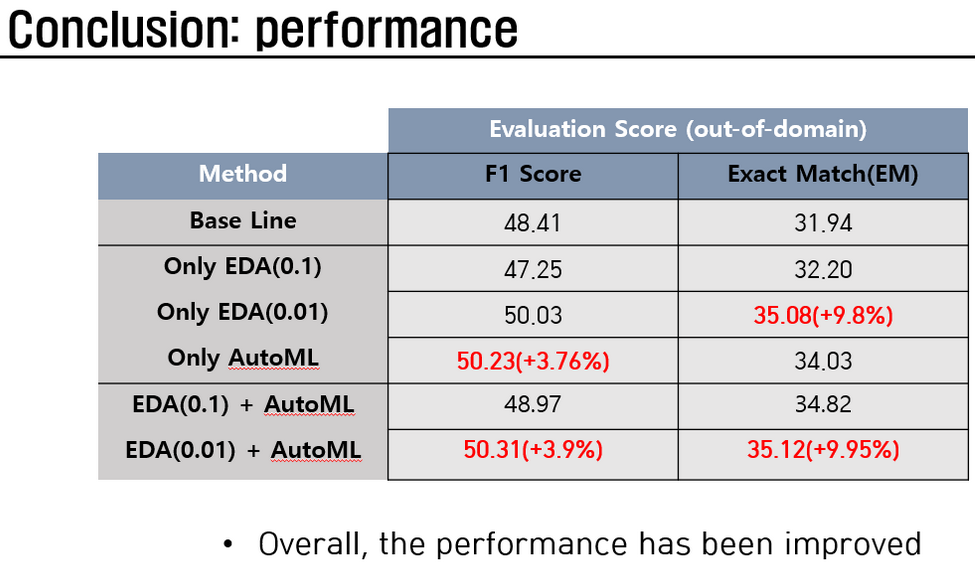
- Final Results
- As shown in the figure below, the performance improved significantly:
- F1 Score: $50.31$ (baseline: $48.41$)
- Exact Match: $35.12$ (baseline: $31.94$)
- As shown in the figure below, the performance improved significantly: